
Understanding process creation in operating system with fork, exec and wait system calls

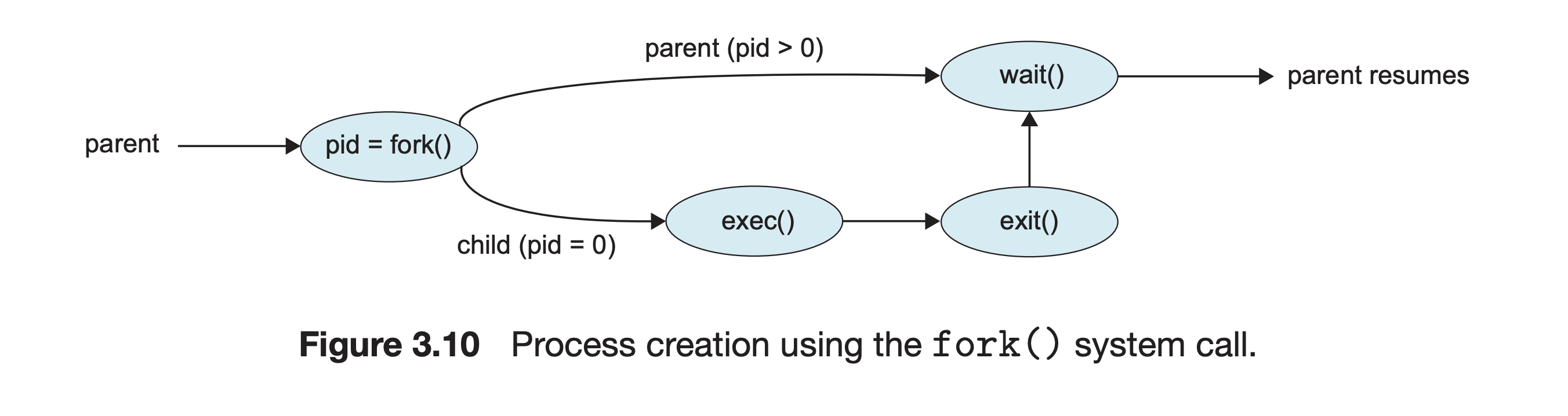
A process begins its life when it is created. A process goes through different states before it gets terminated. The first state that any process goes through is the creation of itself. Process creation happens through the use of fork() system call, which creates a new process(child process) by duplicating an existing one(parent process). The process that calls fork() is the parent, whereas the new process is the child.
In most cases, we may want to execute a different program in child process than the parent. The exec() family of function calls creates a new address space and loads a new program into it.
Finally, a process exits or terminates using the exit() system call. This function frees all the resources held by the process(except for pcb). A parent process can enquire about the status of a terminated child using wait() system call. When the parent process uses wait() system call, the parent process is blocked till the child on which it is waiting terminates.
If you find reading boring, you can watch process creation videos to understand the below concepts.
Fork() System Call
When a parent process uses fork(), it creates a duplicate copy of itself and this duplicates becomes the child of the process. The fork() is implemented using clone() system call in linux which returns twice from kernel.
- A non-zero value(Process ID of child) is returned to the parent.
- A value of zero is returned to the child.
- In case the child is not created successfully due to any issues like low memory, -1 is returned to the fork().
Let’s understand this with some code
pid = fork();
// Both child and parent will now start execution from here.
if(pid < 0) {
//child was not created successfully
return 1;
}
else if(pid == 0) {
// This is the child process
// Child process code goes here
}
else {
// Parent process code goes here
}
printf("This is code common to parent and child");
How Parent and Child Process differs?
A parent and child differs in some of the PCB(process control block) attributes. These are:
- PID - Both child and parent have a different Process ID.
- Pending Signals - The child doesn’t inherit Parent’s pending signals. It will be empty for the child process when created.
- Memory Locks - The child doesn’t inherit its parent’s memory locks. Memory locks are locks which can be used to lock a memory area and then this memory area cannot be swapped to disk.
- Record Locks - The child doesn’t inherit its parent’s record locks. Record locks are associated with a file block or an entire file.
- Process resource utilisation and CPU time consumed is set to zero for the child.
- The child also doesn’t inherit timers from the parent.
If you want to understand the above differences in detail - (fork manual)[http://man7.org/linux/man-pages/man2/fork.2.html#DESCRIPTION]
Is Address Space(memory) duplicated for child?
The answers in no. After the fork(), both parent and child share the memory address space of the parent. In linux, these address space are divided into multiple pages. Only when the child writes to one of the parent memory pages, a duplicate of that page is created for the child. This is also known as copy on write(Copy parent pages only when the child writes to it).
Understanding copy-on-write with code:
int x = 2;
pid = fork();
if(pid == 0) {
x = 10;
// child is changing the value of x or writing to a page
// One of the parent stack page will contain this local variable. That page will be duplicated for child and it will store the value 10 in x in duplicated page.
}
else {
x = 4;
}
In case you want to understand about fork system call in details, watch the below video:
Exec System Call
The exec family of functions replaces the current running program(executable) with a new executable. This is very useful when you want the child process to run a different program than the parent. Take example of the shell program. A shell takes commands as input from the user, runs it and displays the output on screen. Each command corresponds to a new program. The number of shell commands in any operating system is huge. It would be very bad code design to append the program or executable associated with all the available commands in a single program. In this case, the shell(parent process) can create a child process when a user types a command and let the child process execute the command.
/* fork a child process */
pid = fork();
if (pid < 0) {
/* error occurred */
return 1;
} else if (pid == 0) {
/* child process */
execlp("/bin/ls", "ls", NULL); // A new program(ls executable is loaded into memory and executed
} else {
/* parent process */
/* parent will wait for the child to complete */
wait(NULL);
printf("Child Complete");
}
return 0;
Why is exec() system call necessary?
It’s not necessary to use exec() with fork(). If the code that the child will execute is within the program associated with parent, exec() is not needed.
But think of cases when the child has to run multiple programs. Let’s take the example of shell program. It supports multiple commands like find, mv, cp, date etc. Will be it right to include program code associated with these commands in one program or have child load these programs into the memory when required?
It all depends on your use case. You have a web server which given an input x that returns the 2^x to the clients. For each request, the web server creates a new child and asks it to compute. Will you write a separate program to calculate this and use exec()? Or you will just write computation code inside the parent program?
Wait System Call
A process may wait on another process to complete its execution. The parent process may issue a wait system call, which suspends the execution of the parent process while the child executes. When the child process terminates, it returns an exit status to the operating system, which is then returned to the waiting parent process. The parent process then resumes execution.
When the child terminates, the kernel notifies this to the waiting parent using signal(SIGCHLD) and allowing it to retrieve the child process’s exit status.
In the above code example used for exec() system call, the shell(parent process) was waiting for its child to complete. Once the child terminates, it can return the output and exit code of the command to the user.
Why does parent waits for a child process?
- The parent can assign a task to it’s child and wait till it completes it’s task. Then it can carry some other work.
- Once the child terminates, all the resources associated with child are freed except for the process control block. Now, the child is in zombie state. Using wait(), parent can inquire about the status of child and then ask the kernel to free the PCB. In case parent doesn’t uses wait, the child will remain in the zombie state.
The second reason is very important. I will discuss about zombie process in a separate post but you can understand it by watching the below video.
Exit System Call
A computer process terminates its execution by making an exit system call. When the child process terminates (“dies”), either normally by calling exit, or abnormally due to a fatal exception or signal (e.g., SIGTERM, SIGINT, SIGKILL), an exit status is returned to the operating system and a SIGCHLD signal is sent to the parent process. The exit status can then be retrieved by the parent process via the wait system call.
Exit system call is not always implicit in a program. A process can also terminate/return if control reaches the end of the function.
Why is copy-on-write needed?
Since we have covered the process creation in details, we can now understand why copy-on-write is needed.
A typical process creation takes place through fork()-exec() combination. Let’s first understand what exec() does.
Exec() group of functions replaces the child’s address space with a new program. Once exec() is called within a child, a separate address space will be created for the child which is totally different from the parent’s one.
If there was no copy on write mechanism associated with fork(), duplicate pages would have created for the child and all the data would have been copied to child’s pages. Allocating new memory and copying data is a very expensive process(takes processor’s time and other system resources). We also know that in most cases, the child is going to call exec() and that would replace the child’s memory with a new program. So the first copy which we did would have been a waste if copy on write was not there.

Leave a comment